LookFar Labs11 May 2017
Machine Learning for Beginners: An Intro to Neural Networks
In the very first class at Y Combinator’s Startup University Sam Altman is asked what kind of business he would start if he was launching a startup today.
“I would take machine learning and just apply it to a vertical.”
Like cell phones, the gig economy, and big data before it, machine learning will be a key part of the next wave of transformative technology. Machine learning is a sub-field of computer science that gives computers the ability to learn without being specifically programmed to.

Computers do math
A computer is essentially just a machine that can carry out mathematical operations with 100% accuracy at incredible speed. When we say ‘machine learning’ or ‘artificial intelligence’ we’re talking about a specific field of mathematics called ‘neural networks’.
Neural networks have been around since the 1940’s. They involve creating a model and feeding it a large amount of data input and output (we’re talking millions of data points). For example, a data scientist might enter in all barometric data (input) and weather reports (output) for 20 years. The model would then identify patterns and, once trained, actually be able to filter out noise and predict future outcomes from current inputs. Ideally, you could simply enter a barometric pressure into this model and predict the likelihood of rain.
Here’s a representation of a neural network at its most basic:
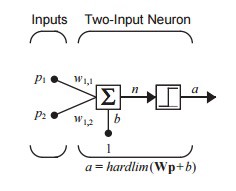
Think of a neural net as a black box. We first input a lot of training data. Then we start adding real inputs and receiving quality predictive outputs that keep improving over time. The important distinction between a neural network and a ‘traditional’ program is that we don’t know or need to develop the equation the computer uses to predict outputs. The neural networks writes the equation for itself (or “trains” itself).
For really sophisticated neural networks, which can see hundreds of inputs, the data scientist doesn’t even know which input the network is actually using to create the predictive output.
Here’s a simple script I wrote in college to model a neural network; It doesn’t matter if you get what’s going on in the script. I didn’t either. I barely passed the class. What’s important is that you see that this is math, not Skynet.
Chess vs. Go: A Semi-Technical Example
Computers have been beating humans at chess since 1978. However, a computer was not able to defeat a human at the game Go until 2016.
Go is a board game that was invented in Asia before the Zhou dynasty (2,500+ years ago). Go was long hailed as a prime example of a game at which a computer couldn’t beat a human. While a computer is really good at solving problems, it needs an equation in order to produce a solution.
The difference between Go and chess is that while chess has rules that are static and well defined (making the equations programmable), the rules (read: equations) used to solve Go are created while the players are playing. Even though Chess has an equation that is very complex, once computer processing became fast enough it could solve the game faster and more efficiently than a human could.
From Theory to Everyday Use
So why are we just hearing about machine learning in the last few years when the idea has been around since the 1940’s?
1) Real world systems have many inputs, not just one. Barometric pressure alone isn’t an absolute indicator of rain. There are many, many more inputs needed to produce an “it will rain” (0) or “it will not rain” (1) output with any degree of accuracy. Neural network logic still works with many inputs, but an increased number of them exponentially increases the complexity of the network and the amount of calculations that need to be done.
2) Heavy calculations. Millions of data points with hundreds of inputs are needed to reliably train a model. Consumer computers are just reaching the point at which they are powerful enough to carry out a technical lift of this magnitude. We’re also just beginning to get access to a large, reliable cloud system (network) to carry out this type of computing.
3) Not enough data to train the neural network. We’re talking about some really serious data that hasn’t become available until just recently. Large companies like Apple, Google, and Facebook (and the NSA…) are going to be leaders in machine learning simply due to the data they have collected to date.
4) Lower hanging fruit — machine learning is hard and resource intensive. Until recently, smart people have prioritized leveraging new internet or mobile opportunities rather than innovating in this field.
However, open-source frameworks and tools (most notably from Amazon) are being released every day. These tools lower the barrier to entry significantly. You don’t need to write a machine learning program from scratch, instead you just need to source one of these services or tools and adapt it to your specific need.
A Real World Example
A friend of mine works for a machine learning service company that just landed the account for a prominent drug store. The drug store approached my friend’s firm to help them increase efficiencies in their inventory ordering. At present, they order the same inventory every month – think raincoats in summer, cheap fleeces in the fall. Through machine learning, they were able to integrate the drugstore’s inventory patterns and sales data with open-source weather data, allowing them to better predict what they order and make their supply chain more efficient.
I fully expect this type of machine learning to be applied across almost every industry vertical over the next 10 years. A few recent examples:
Detecting sentiment via Tweets, used to make recommendations on stock choices
Google Maps can indicate parking scarcity using machine learning
Brain scans are being used to indicate who will be diagnosed with Alzheimer’s in the future
We’ve been working on a neural network to help refine ultrasonic data transmission. If you’d like to learn more, contact us!
Written by
 Signal-Based Selling FTW with Creative Service Agencies
Signal-Based Selling FTW with Creative Service Agencies
 Build vs. Buy: Third Party or Custom-Developed Software
Build vs. Buy: Third Party or Custom-Developed Software

Copyright © 2025 LookFar Labs. All rights reserved. Privacy Policy