LookFar Labs28 January 2016
Ultrasonic Data Transmission: So Much Harder Than It Should Be
Why We’re Working on Something that No One Can Get Right
There’s a lot of truly mind-boggling tech out there – rail guns, self-driving cars, hover boards. So why is ultrasonic data transmission – use of sound beyond the audible spectrum – pretty much stuck at about the technical equivalent of the dog whistle?
There’s clearly a strong desire in the tech community to get this tech working. In February 2014 Google acquired SlickLogin, a Tel Aviv start-up that used ultrasonic tones as a second factor for password authentication. They were acquired just five months after launching, the team absorbed into the amorphous blob of Google geniuses.
As far as we know, Google dismantled the SlickLogin software, but they’ve still been attempting to bring the technology to market. The struggle now is finding a use case that makes sense. In summer 2014 Google announced that the ChromeCast would allow guests to log in via an ultrasonic pairing signal. There was a lot of fanfare at the launch but the product pretty much fizzled into obscurity. After all, asking someone for their WiFi password just isn’t all that difficult.
Then in summer 2015, Google launched Google Tone, a product of Vancouver Googler Boris Smus. The use case this time? Sending URLs to nearby computers, allowing you to silently rick-roll your office. According to Smus’ blog and Github, he’d been working on the pet project since 2013. Although Google Tone was #1 on Product Hunt the day it launched, we haven’t heard much about it since.
The idea of sending data – even very small bits of data – via sound, is technically appetizing. It’s practically hardware agnostic – every phone has a microphone, and it doesn’t require WiFi, Bluetooth, Rubee, or any of the other near-field communication (NFC) protocols that are already out there. As people cut cords, cancel newspaper subscriptions, and download ad blockers, proximity based marketing is becoming more and more attractive for reaching consumers. But even with behemoths like Google and (allegedly) Qualcomm working on it, nobody seems able to successfully master ultrasonic data transfer.
We’ve been working on our own ultrasonic data transmission app for nearly a year and a half. It’s called Tchirp and we initially thought of the idea when wandering in the French Quarter.

You walk into a club and love the band that’s playing. But its late, it’s crowded, and Shazam doesn’t work for live music. If you’ve got ultrasonic data on the brain, there’s a solution; just encode a unique artist ID in ultrasonic sound, like an audio-based QR code. You’ve got the speakers on stage, and a computer with attached microphone in the form of a smartphone. All the hardware is already in place. Sounds easy enough, right?
I wish.
…Just to Put Things in Perspective
Anyone who has ever glanced at the equations for acoustic physics can tell you that the science of sound gets complex very quickly. We’re talking about pressure waves moving through air and interacting with each other as they bounce off of some surfaces while being absorbed by others. And in case that was too straightforward, many of these interactions depend on frequency, angle of contact, and even the temperature and barometric pressure. And we are trying to introduce specific frequency waves into this system and detect them from elsewhere.
Imagine a swimming pool with a dozen kids splashing around. And on one end of the pool we’re going to make a specific splash, and from the other end of the pool, we’ll try to detect that specific splash. Not so easy.
But let’s drill into the specifics. Here are a few of the specific issues we ran into.
Problem 1: Audio Hardware Limitations
For our proposed solution, we need to broadcast the identifier (as ultrasonic sound) into an environment. We want this signal to be as strong as possible, but there are limits. An audio system can be overdriven which results in clipping. You’ve heard clipping if you’ve ever turned your speakers all the way up and the sound starts to get grainy. This can occur for a number of reasons, but the result is always the same: added frequency components in the signal. This complicates the signal detection and can cause an originally ultrasonic transmission to become audible. Also, sound systems do not respond equally well to all frequencies. And because Tchirp works in a band of sound almost no humans can hear, most audio systems are tuned to attenuate (“quiet”) these very high frequency components (this is referred to as “roll off”).
We see the same problem on the signal detection side. Microphones each have their own characteristic roll off, and will detect audible frequencies with greater ease than ultrasonic frequencies. And since the responsiveness characteristics of microphones vary depending on the frequencies to which they are exposed, we don’t get the same magnitude measure for two different frequencies even if they are played at equal intensity.
To handle this we multiply our frequency magnitudes against a function that attempts to equalize the response of the microphone across all frequencies in question. This gain curve must be calculated or estimated for each device on which the Tchirp receiver is operating. This process then leaves us with a single measurement for each frequency used by Tchirp which accurately represents the energy in the signal at the frequency in units which should be roughly the same no matter the basic level of sound in the environment.
We don’t use any sort of standard curve for microphone roll off. We scale each frequency independently based on trial and error.
Finally, most speakers and microphones are responsive to the frequency range of 20 Hz to 20 kHz which is more than enough to account for the range of human hearing. However, this means that our usable bandwidth of ultrasonic frequencies is small. The number of frequencies we can produce/detect at one time is limited. If, for example, your standard speaker and smartphone mic had a range extending to even 22 kHZ, that would roughly double the usable bandwidth. But since a primary attraction to ultrasound communication is largely based on the ubiquity of the equipment, this is an issue which will likely persist.
Problem 2: Computational Power of Smartphones
Smart phones are extremely powerful computational devices, but they still lag behind desktop/laptops when it comes to pure data crunching. Also, there is extremely limited RAM by modern standards. And users have come to expect fast responses from their apps. For the device broadcasting a “tchirp”, this is no problem. A combination of additive synthesis and wavetables means we can produce tchirps without using very much memory. However, the tchirp receiver is a whole other case.
We need to record some audio, analyze the frequency content, determine if it is a tchirp, decode the payload, and repeat, all the while presenting an animation on screen for the user. And this process repeats thousands of times per minute.
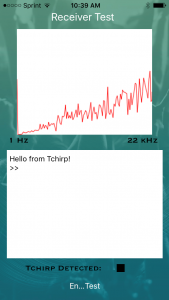
The longer the amount of recorded audio, the greater precision we can achieve with frequency analysis. However, more recorded audio also requires greater processing time in the analysis phase, which is done on your smartphone. Many mobile devices simply lack the computational horsepower to simultaneously record audio, store it, and perform frequency analysis. This means we have to shut down the record feature while we process, which means missing new tchirps.
We continue to tune the system so that we have a fast response time and high precision during the analysis phase. We’ve found the system works best when we use 1024 samples of audio at 44100 samples per-second for each loop in the receiver. A power of two is necessary for the Fast Fourier Transform to function properly. As smartphones get better, we anticipate this being less and less of a problem.
Problem 3: Scalability
We have limited bandwidth and limited computational horsepower, and we need to broadcast and receive a unique identifier in under 5 seconds (so our user doesn’t get bored and give up). Considering that audio transmission through the air is inherently slow compared to over-the-wire, we need to cram a lot of information into each tchirp. But the limits of audio hardware only gives us about 2000 Hz of bandwidth, and the computational limits of smartphones means we can only break this into about 45 distinct and recognizable frequencies.
Add to this the problem of frequencies interacting in the environment before the receiver records them, and you quickly come to find that adjacent frequencies are not likely to be distinguished when broadcasted simultaneously. With that, we’re down to less than 10 usable frequencies which could, in theory, be broadcasted and identified at the same time. And of course, due to the roll off we discussed earlier, some speakers and microphones will be more responsive to some of these frequency components than others. For example, the speakers and iPhone we used for initial tests detected 19293.74 Hz way better than frequencies just above or below that. In fact, that frequency was the one used in successful tests at a loud music festival and in a noisy bowling alley.

The most stable transmissions are those which use no more than 3 of these frequencies; tchirping works pretty well when you limit the signals in this way. However, the usefulness of Tchirp, and any ultrasonic protocol, is based on the ability to send a unique identifier that is connected with a piece of information (in this case, a band or artist’s profile) in our database. The receiver listens and recognizes the tchirp, and then uses WiFi to connect to the database and retrieve the information associated with the identifier (again, like a QR code does with a visual signature).
If we can only transmit one frequency with a relatively guaranteed success rate, then we can really only send out one piece of information at a time. Of course we could use a geo-location hack-around to serve the correct content, but that doesn’t solve our core problem. A single frequency would be enough for serial data transmission, but we need more data than that can carry in the given time, and that introduces a host of problems related to timing between the sender and receiver.
Even with three successful frequencies, that gives us only 8 possible Tchirp combinations. So that means, if we implement a system that recycles identifiers, only eight people could be using our product at any given time. I haven’t yet gotten up the courage to hop on stage at any pitch competitions and tell potential investors that we have a potential user base of 8.
Problem 4: Android
I’m an Apple guy. I make a living writing in Swift and Objective-C. The iPhone has been around since 2007, and there are still only 6 or 7 versions. Really, only 3 currently matter. When writing software that has to integrate with hardware this is the perfect scenario, because all iPhone microphones are roughly the same and integrate with roughly the same software.
Not the case with Android. There are tons of different Android models by different companies with different microphones. It’s impossible to predict how they will interact with Tchirp and how the microphones will process the ultrasonic frequencies. I’m super impressed with companies like Chirp.io that seem to work with both Apple and Android. We now have an Android developer working on the project. Thank god.
So Why the Heck Does LookFar Keep Working on Tchirp?
If you pay attention to Silicon Valley news on any level (or you have a Product Manager who forwards you relevant patents all day long) then you probably heard about the rise and sordid fall of Clinkle.
Clinkle was a great-on-paper startup founded a few years back by a Stanford student whose dad worked in the industry. They were able to raise a $35M seed round (then the largest of all time) on the premise that they could build almost this exact technology.
Clinkle wanted to use ultrasonic data transmission for mobile payments. A phone would make a clinkle, the register would pick it up, and then it would scan the database for a unique identifier and charge the card associated with it. It was an idea with a lot of promise (they were funded before ApplePay, GoogleWallet, etc. came out) but they could not get the tech to work. They spent several years pivoting around the fact that they couldn’t transmit the identifier in a crowded coffee shop, or while someone was blending a smoothie.
Both tech and tabloid-worthy leadership issues contributed to Clinkle’s demise, but just knowing that someone gave an unproven team a $35M seed round for a mere whiff of this technology validates our belief that ultrasonic data transmission is something the world wants, and possibly needs. The uses of ultrasonic sound are essentially endless; in an environment where data can be transmitted by sound, you won’t need WiFi to make a payment. Protesters will be able to communicate even if, say, an oppressive government shuts down the internet. Information can be transferred between mobile devices via ultrasound – all at the click of a button.
So for now, I’ll continue to beat my head against the ultrasonic wall.
Written by
 Signal-Based Selling FTW with Creative Service Agencies
Signal-Based Selling FTW with Creative Service Agencies  Build vs. Buy: Third Party or Custom-Developed Software
Build vs. Buy: Third Party or Custom-Developed Software